Last updated at Tue, 20 Aug 2019 13:07:55 GMT
This blog was previously published on blog.tcell.io.
This post kicks off a series we’re doing on serverless security, since it’s one of the hot trends in application development. Over the next several weeks, I’ll be writing about what serverless is, what types of applications benefit from it, and the security considerations you might have when building your application on bleeding-edge technology.
Serverless model
Serverless computing, sometimes called “Function as a Service” (FaaS), lets you write small self-contained functions that can run independently. Here’s what the basic model looks like:
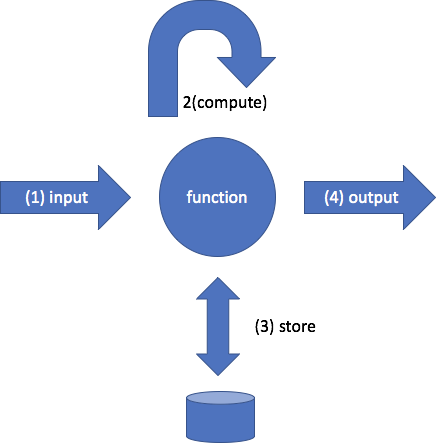
Your function takes some inputs, performs computation on the inputs, stores and retrieves state, and produces output. This is what code has done since code was invented, so what’s new about it?
Well, the biggest thing is that FaaS architectures shift some of the security responsibility from you back to your FaaS platform provider. A rough division of labor is shown below, with your application in blue and the FaaS platform in yellow. It sounds like a great deal: you write a function, and somebody else is responsible for lots of the hard work: finding servers to run it on, keeping those servers up-to-date, cleaning up after server compromises, automatically adding servers when the load gets too high, figuring out how many functions can run on a server and redistributing loads as required, and building a network fabric that can handle the communications between functions and all their support services.
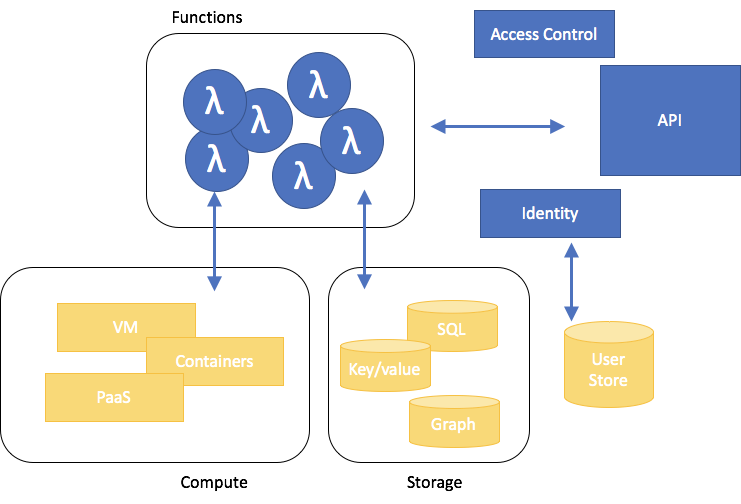
The down side of this shift in security responsibilities is that you are now definitely required to focus on securing your own code. Functions now need to stand on their own. Developers can hook any function up to any other function, so there isn’t always going to be a clear place to sanitize inputs that might come from attackers. In fact, the inputs to serverless applications can be much wider-ranging. Instead of a well-defined chain of functions, you might have to deal with REST inputs over HTTP, different types of message queues, and extensible protocols that change with every release.
New risks
Serverless computing models introduce new risks, and traditional tools have not proven extensible in dealing with some of these risks. The OWASP Top 10 remains a good framework for protecting applications, but many of its attacks are based on the idea that your application runs on servers and that your responsibility extends well beyond your own code to include the entire platform.
Some risks stay the same. Attackers will attempt to inject malicious data into your application, whether as they always have (SQL/database injection attacks) or by injecting data directly into a function. Functions may have been given excessive privileges or have insufficiently strong authentication. Like all code, functions may depend on vulnerable components and be poorly designed.
Serverless architectures add new risks because functions can be triggered by APIs, events in a queue, or even events in storage systems. As a result, the execution flow of a serverless application may not be obvious, and the attack surface is somewhat more complex and varied. Security tools have not yet adapted to the on-demand nature of functions with many kinds of inputs. SAST, DAST, and IAST are most useful when used for well-understood classic HTTP interfaces. Serverless functions are difficult to apply when functions can call each other and be triggered by events because the flow analysis performed by analysis tools is an NP-hard problem.
As a start, let’s look at the OWASP Top 10 and see how it applies to serverless computing:
1. Injection
Sending untrusted data to an application in the hope that it is executed is magnified by serverless architectures. Functions are invoked by a plethora of methods. Conceptually, using an API gateway to handle a request with a function is clear, but serverless platforms allow functions to be launched by storage events (new or changed files or database fields) or message queues. Any of these triggers can include input from attackers, and consequently, injection attacks are top of mind in serverless computing.
2. Broken authentication
As with the previous vulnerability, broken authentication in serverless functions can have wider exposures. Traditional applications will typically authorize access to the entire application, and use one token for all functions in an application, and even when implemented as microservices, an overall unified authentication architecture controls access to the application and all its functions. When microservices are further decomposed into functions, each function becomes a nanoservice, and has its own set of access controls. When a user accesses an API endpoint that flows through several services and writes to storage, each link in the chain may need its own form of authentication.
3. Sensitive data exposure
Serverless applications can expose sensitive data that is weakly protected. One challenge to securing a serverless application is that sensitive data may need to be available to many functions, and therefore, it will be necessary to share API keys, encryption keys, or credentials to external services across several functions, and it may be difficult to do so securely. Cloud providers have “key vault” systems to share secrets throughout an application, but they are new and may not be well understood by development teams.
4. External entities (XXE)
Many serverless applications are built on less complex data formats than XML, such as JSON, and therefore, this OWASP top 10 risk will not be as pronounced for new applications.
5/6. Broken access control and security misconfiguration
As with many items on the OWASP top 10, these two present a larger challenge in serverless computing than in traditional models. A typical serverless application will be constructed as a chain of functions. An input is given to a function, which may interact with several external data stores to create an output. So far, that’s the model of the previous diagram. Building the entire application on FaaS platform, however, leads to chains like this:
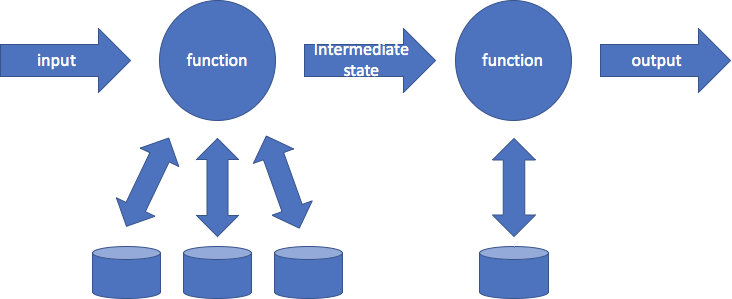
Configuring functions properly for secure deployment can be a challenge because each function — and all the services it interacts with! — needs a specific security configuration. Think of the number of open S3 buckets that make the news. A few years ago, Rapid7 found nearly 2,000 open buckets, each of which might contain the output of a function chain. Why break into the function when you can just read its output? Yes, you can limit the privilege of a function, but then configuring least privilege for every possible function is a complex endeavor.
7. Cross-site scripting
Web-based applications built on serverless platforms are still vulnerable to XSS attacks because attackers may still target end users and their browsers. Implementing an application on serverless, however, does not dramatically change the risks of an XSS attack.
8. Insecure deserialization
Like XXE, deserialization attacks work by embedding code in a payload. Because functions can be called in any order, there is not always a clear place to sanitize user input. As a result, data sanitization should be more widespread in serverless applications because no function can trust its input.
9. Using components with known vulnerabilities
This is essentially the same in serverless as traditional approaches. Understanding what packages your application depends on can help manage risk.
10. Insufficient monitoring and logging
This is at the bottom of the OWASP top 10 because it’s generally straightforward to build a logging system when you control all the code. With a serverless platform, or cloud platforms in general, you can rely on the cloud platform’s logging capabilities, but best practices for logging in cloud platforms (not to mention in serverless!) are still evolving. Your choice is to rely on the logging tools from your cloud platform, or to build additional logging in to your application. In either case, many log analysis tools have not yet built cloud-aware logging capabilities.