Last updated at Tue, 25 Apr 2023 21:13:52 GMT
Tod Beardsley dropped some solid knowledge on the occasion of CVE's 100,000th entry. But, there are many ways to mark this Large Random Number event, and I thought a deep-dive into some meta-analyses of the evolution and make up of the CVE ecosystem would make for a great companion to Tod's post.
Let's start with a fact that is (mostly) now well-known by infosec professionals: CVE count data is — er — problematic. For a long, long time, CVE was in the capable hands of a small number of researchers and experts over at MITRE who were making a real and valuable effort to "science-up" vulnerability tracking. Having a standard taxonomy (a fancy term for agreed-upon terms and categories) makes it possible to have common discussions, analytical approaches and uniform reporting in security products. However, when there are only a handful of folks dealing with the vulnerability ecosystem, there can only be so many CVEs at one time. That makes to use CVE "counts" to prove one technology is better or worse than another is just silly, since they were handled either opportunistically (i.e. when they became aware of an issue) or determinstically (i.e. by folks with a research curiosity in one particular area — think Java, Microsoft Windows, etc.).
So, rather than look at counts, we're going to take a look into the evolution of the CVE ecosystem and present some views you may have not seen before, with the hope that it inspires you to see CVE through new lenses and work towards making the ecosystem even better in the future. We're really going to need that with all of the network- and internet-enabled devices proliferating like Tribbles.
CVE Growth
There's been pretty steady growth in the pace of CVEs. Looking at the year-month counts, we can see a sharp uptick in the monthly counts starting in 2017:
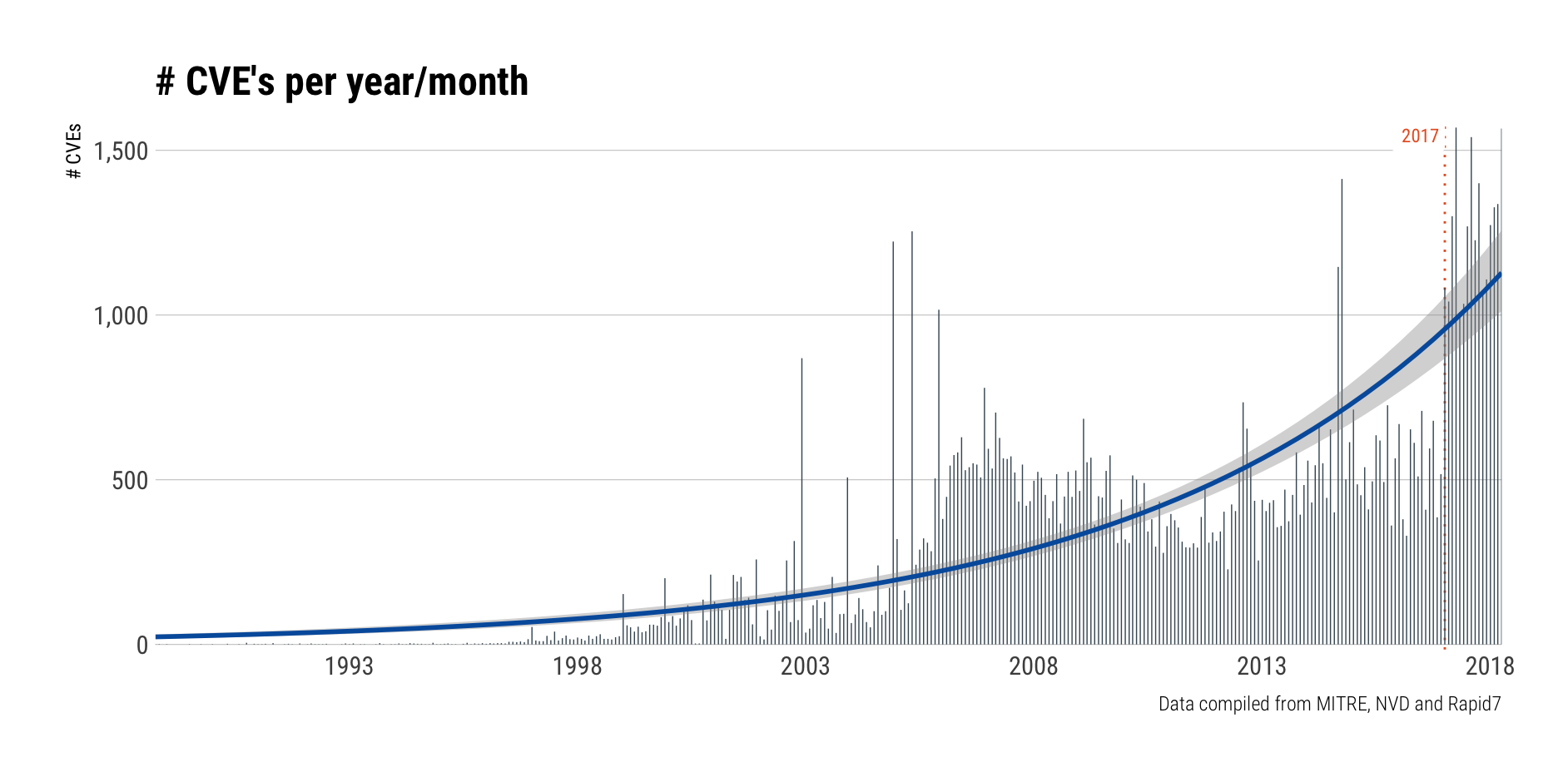
Part of that growth is due to new Certified Numbering Authorities (CNA), but a good chunk of it is the traditional "heavy hitters" doling out even more vulnerabilities than they have in previous years.
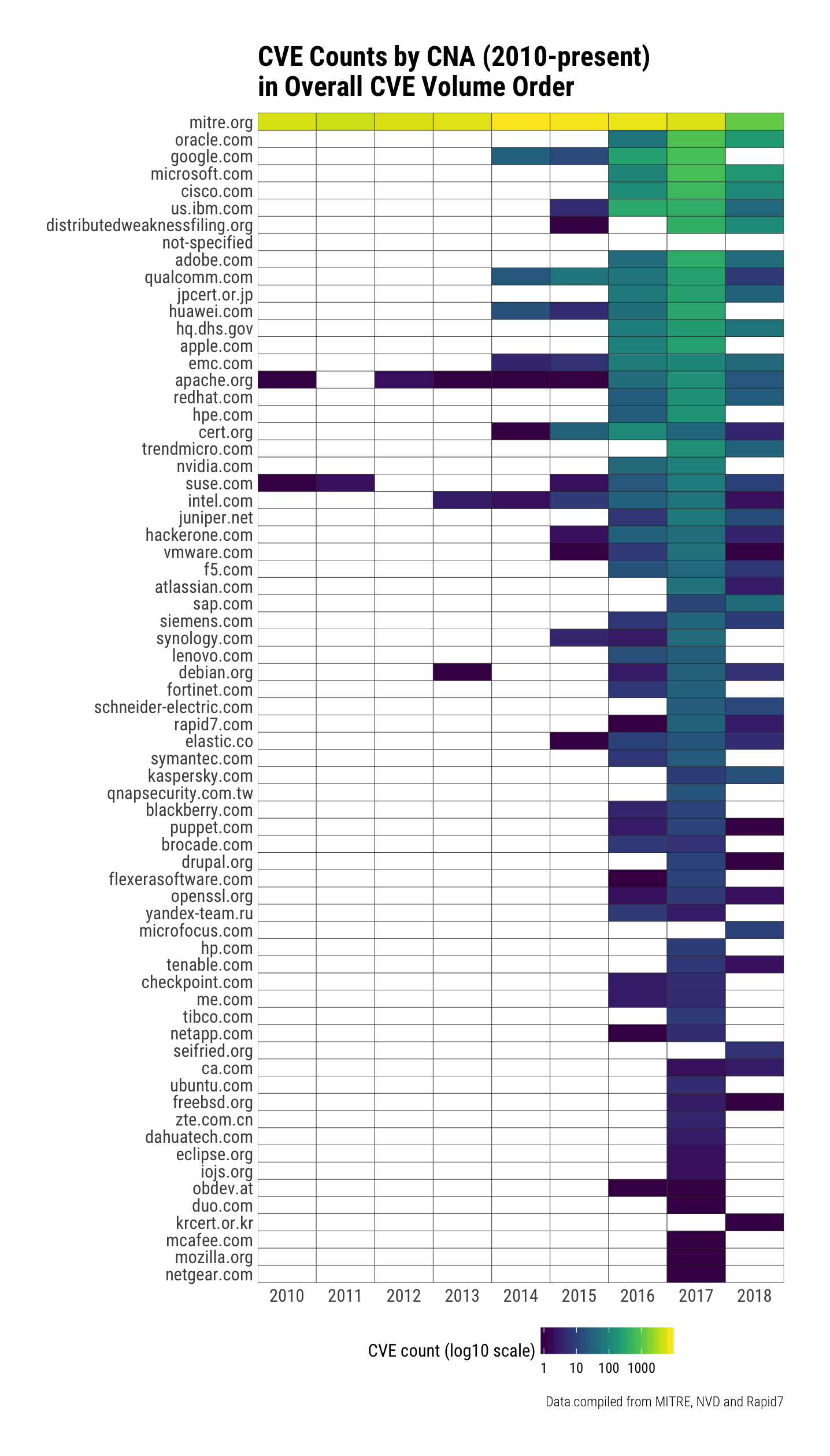
Note that this list is based on who is assigning vulnerabilities; some companies like Rapid7, Cisco, and a few others assign CVEs to both their own products and to for vulnerabilities they've found in other products.
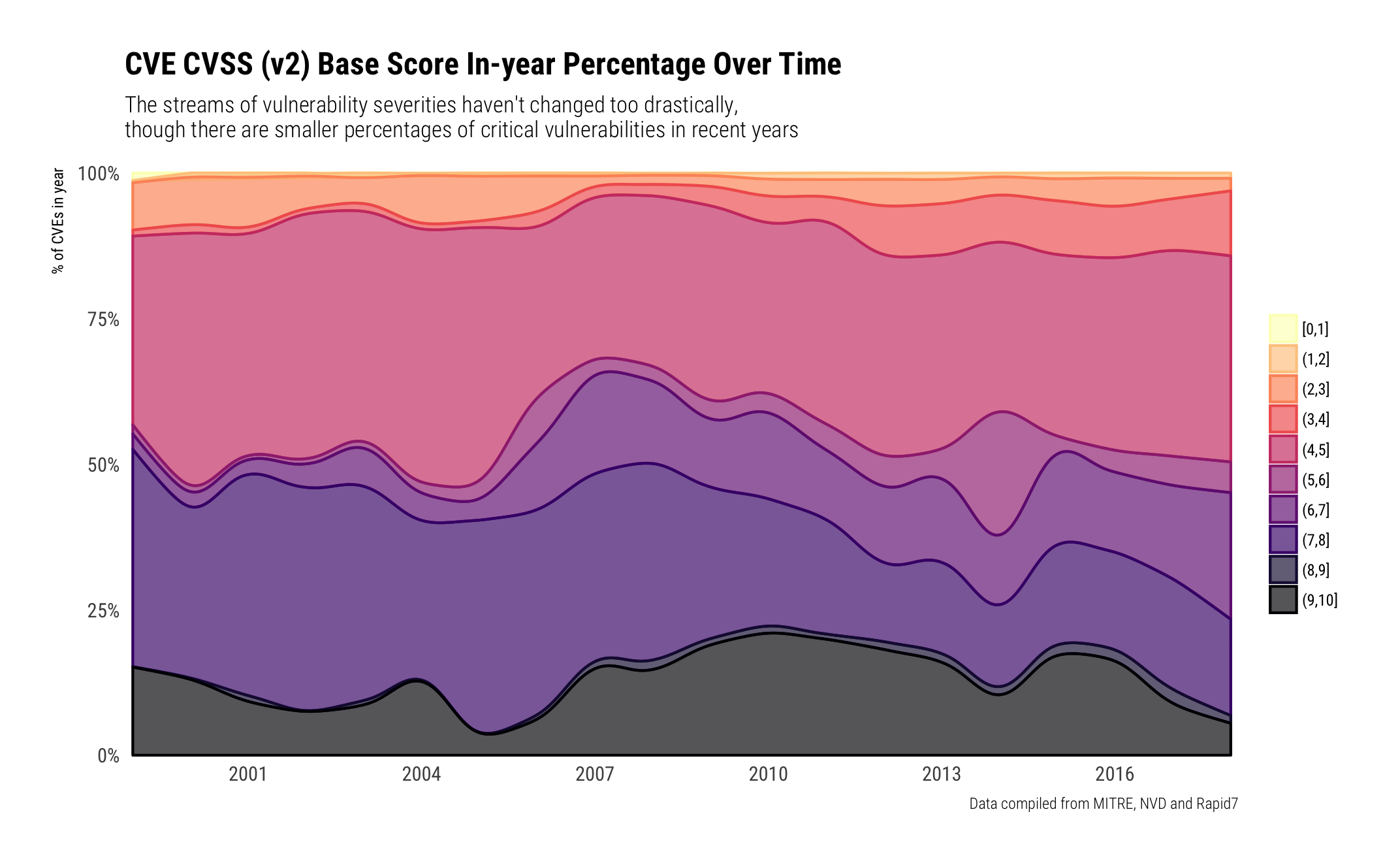
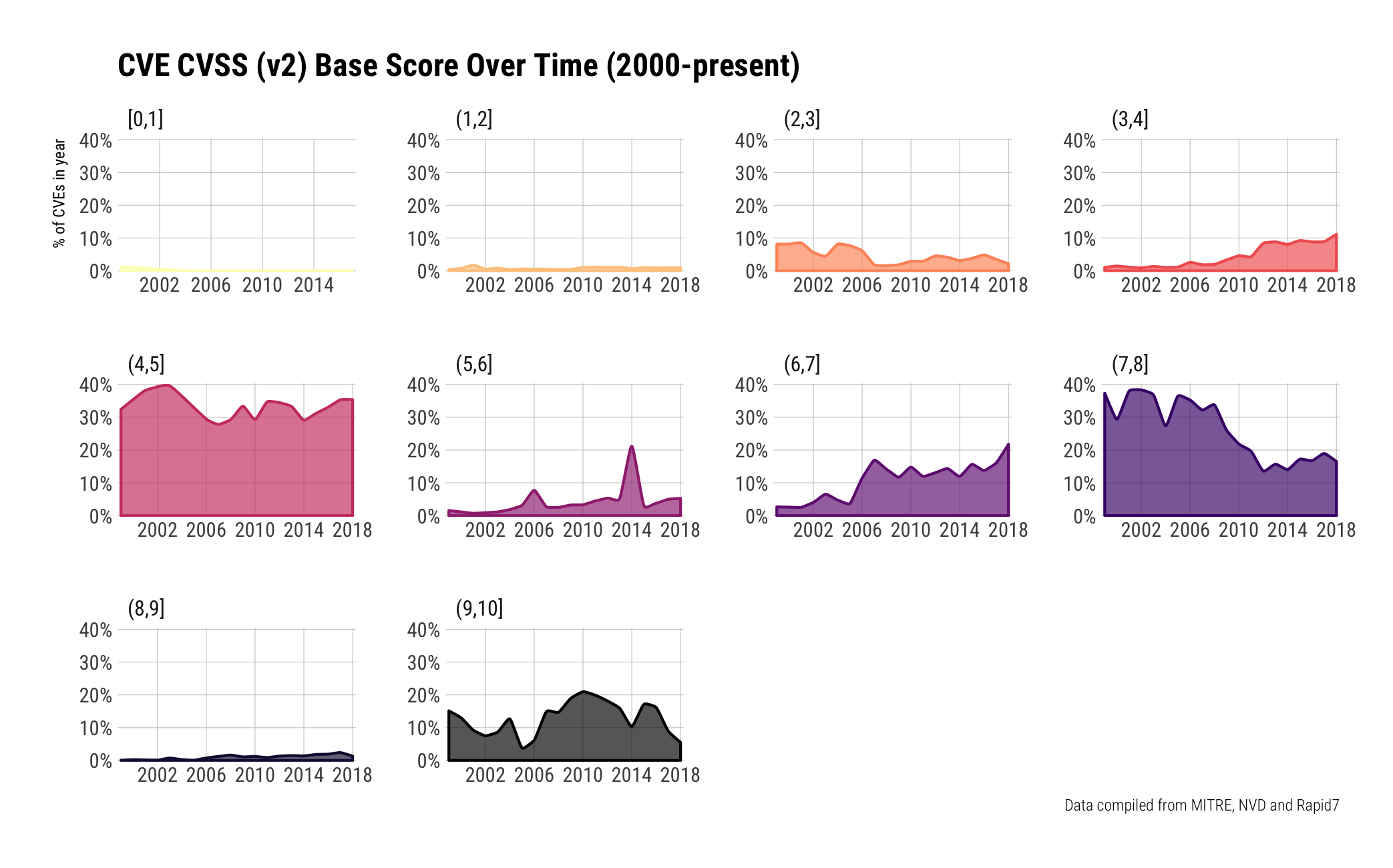
The passage of time hasn't done much to the in-year breakdown of severity. We're using CVSS V2 scores since they are the most populated field across all years.
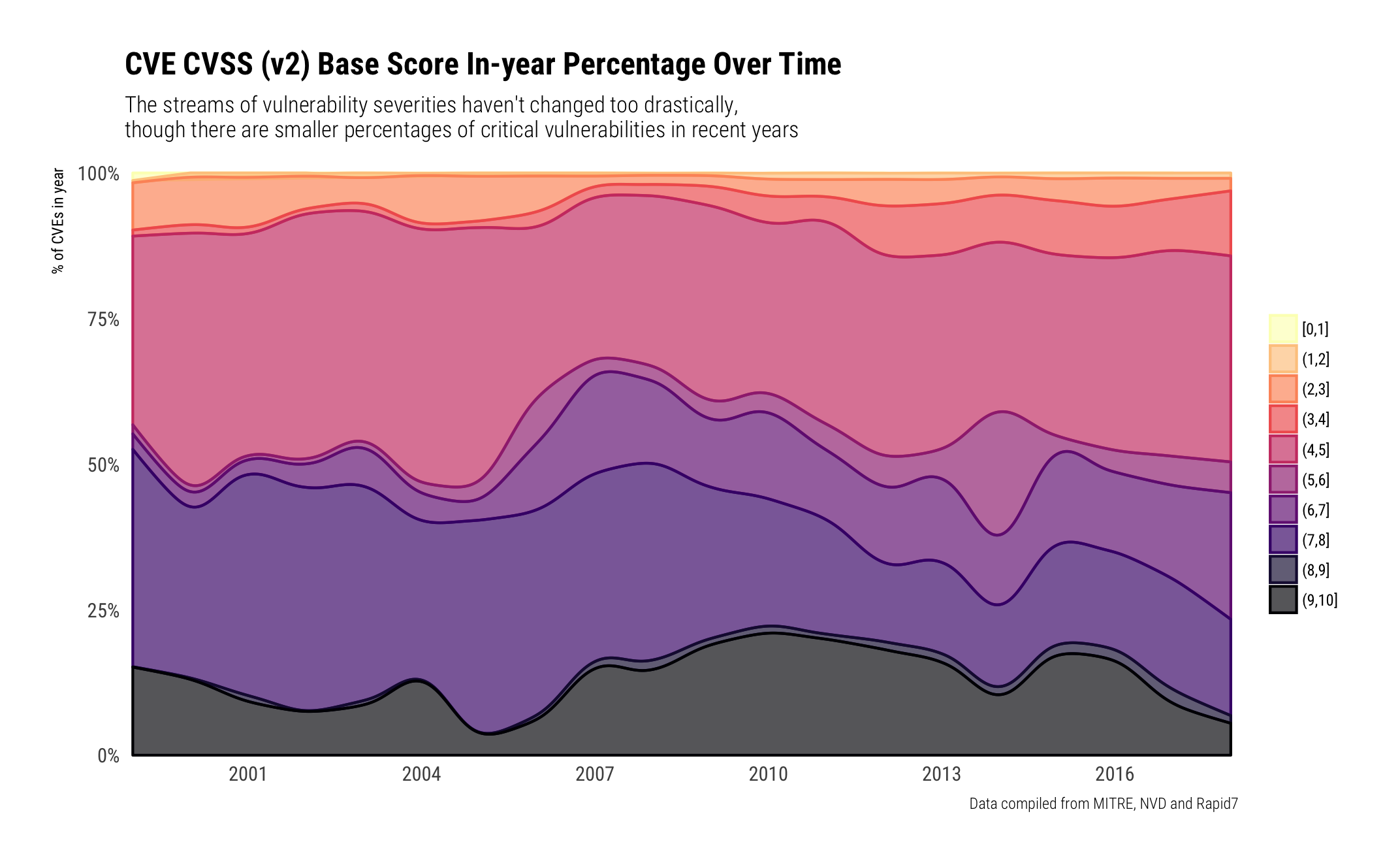
They're generally clumped into the (4,5] / (6,7] / (7,8] / and (9,10] with more in-year percentages of vulnerabilities being assigned a medium-high — (6,7] — rating:
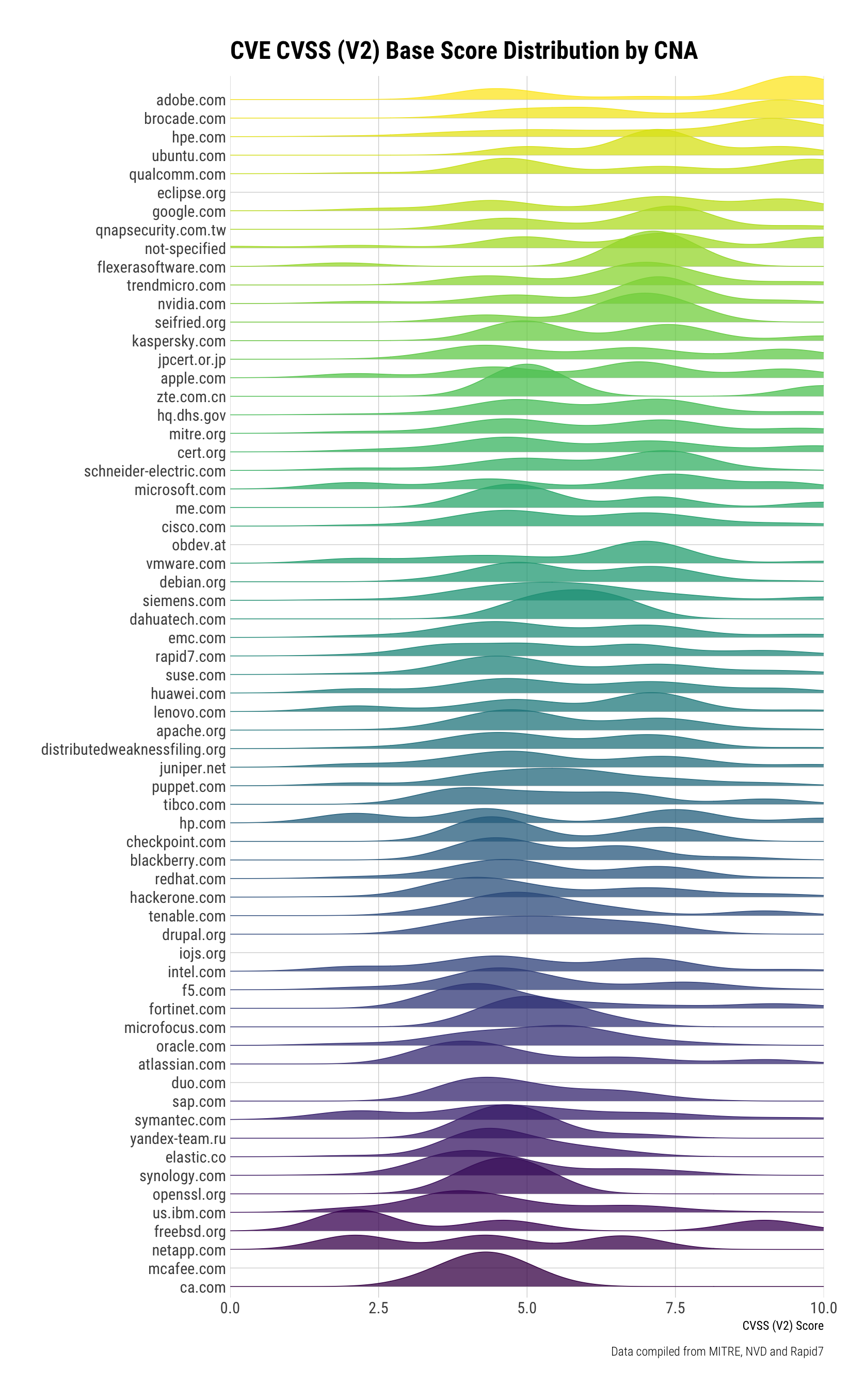
There are also some "trends" by CNA. "Trends" is in quotes since the CVE system is still maturing and entries are fairly (still) ad-hoc. That is, when a CNA or individual has time, opportunity and effort, CVEs get made. When they don't they don't. When we look at the CVSS V2 ratings distribution per-CNA some features come as no surprise:
- Adobe has either "meh" or ZOMGOSH vulns;
- Microsoft has more diverse severity distribution as they span their entire product line;
- Most CNAs have a bimodal (2 favorite severity ratings areas)
- Some — like Symantec, Synology, and CA really the middle ground.
Digging Deeper
MITRE has another great project — the Common Weakness Enumeration (CWE) standard. They "serve as a common language, a measuring stick for software security tools, and as a baseline for weakness identification, mitigation, and prevention efforts". Unfortunately, most CVEs still do not have CWEs assigned to them, but some do and we can use them to look at some more detailed trends (keeping an eye out for areas with too few observations).
For a while (2008-2016) NVD used a set of CWEs when assigning CVEs, though most NVE CVE entries still do not have a CWE assigned to them:
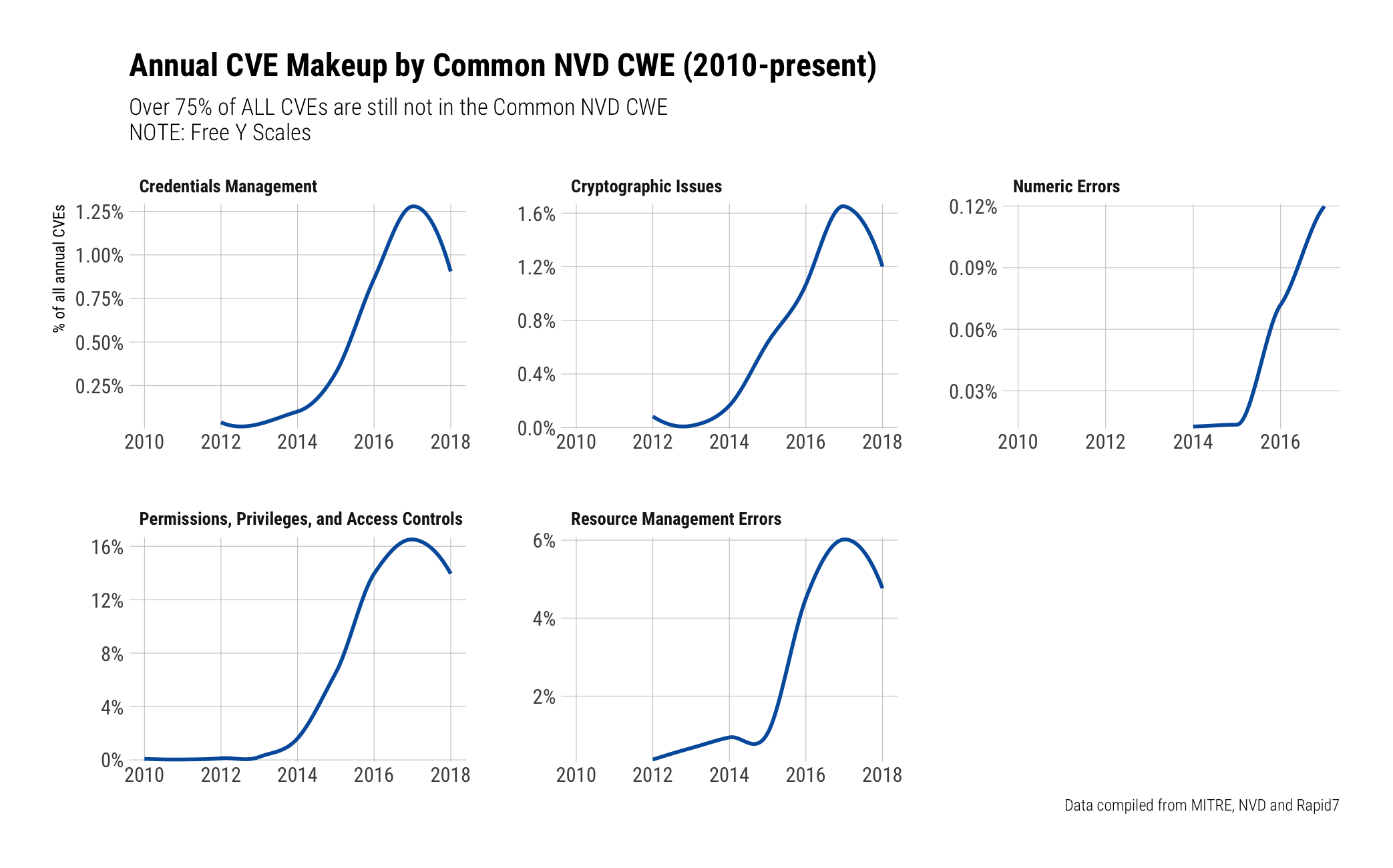
Out of all the panels we can make some useful observations on the bottom two ("Permissions" and "Resource Management Errors") in that there seems to be a decent chunk of CVEs that relate to:
- Privilege / Sandbox Issues
- Improper Ownership Management
- Improper Access Control
- Exposed Dangerous Method or Function
or what could be summarised as "DoS/Overflow" issues:
- Uncontrolled Resource Consumption ('Resource Exhaustion')
- Improper Release of Memory Before Removing Last Reference ('Memory Leak')
- Transmission of Private Resources into a New Sphere ('Resource Leak')
- Improper Resource Shutdown or Release
- Asymmetric Resource Consumption (Amplification)
- Insufficient Resource Pool
- Resource Locking Problems
- Double Free
- Use After Free
- finalize() Method Without super.finalize()
- Free of Memory not on the Heap
- Free of Pointer not at Start of Buffer
- Mismatched Memory Management Routines
- Release of Invalid Pointer or Reference
- Improper Control of Dynamically-Managed Code Resources
NVD switched to a more "modern" list and has been doing a much better job at assigning those CWEs to CVE entries (though ~50% still do not have even one CWE assigned):
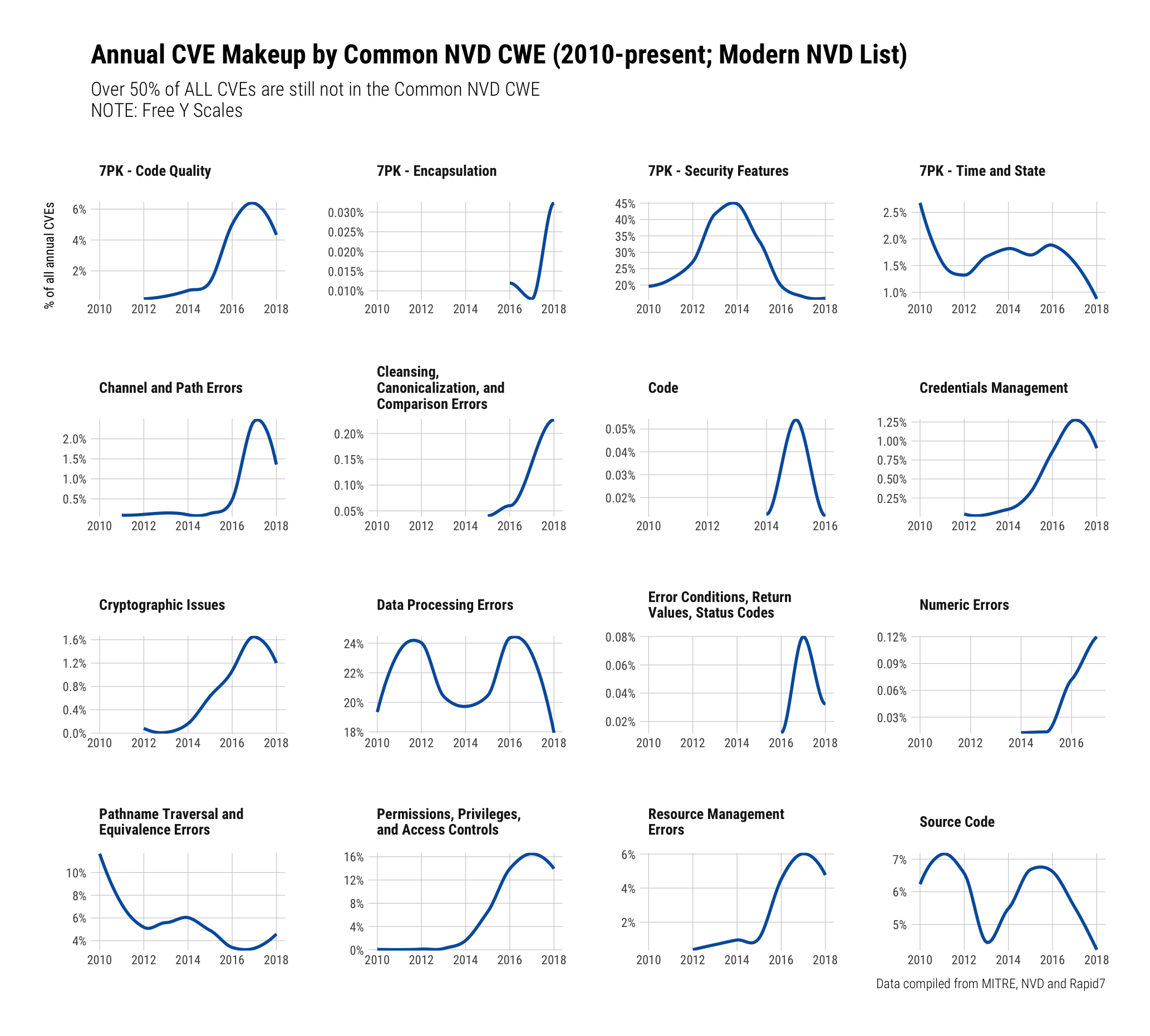
"Code Quality", "Pathname Traversal", "Permissions", "Resource Management" and "Source Code" (dig into all those here make up most of the 50% that have CWEs.
We can also use other CWE research concept areas to take a look at how various CWEs relate to the CVE ecosystem.
Seven Pernicious Kingdoms
Katrina Tsipenyuk, Brian Chess and Gary McGraw developed a "coding error" taxonomy dubbed the "Seven Pernicious Kingdoms" (7PK). Taxonomies are great as they enable researchers to take a more scientific look at the trends while also providing uniformity for software assurance tools that developers use.
We're in the same boat with the 7PK when it comes to CVE tagging as you'll see in the chart below.
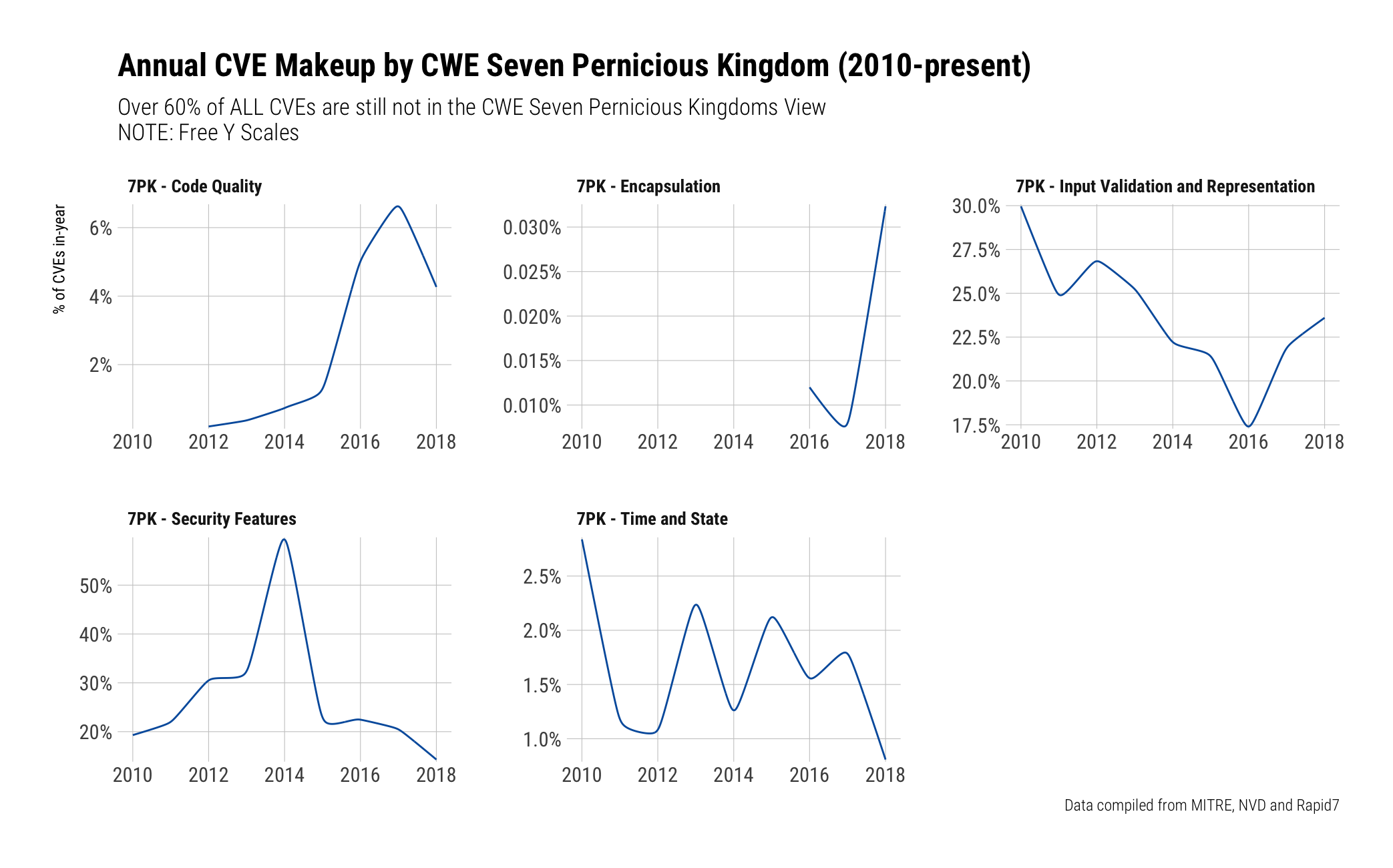
Only a handful of the "kingdoms" are represented and in there, only two: "Input Validation and Representation" and "Security Features" really provide much value. They are comprised of:
- Unprotected Storage of Credentials
- Empty Password in Configuration File
- Use of Hard-coded Password
- Password in Configuration File
- Weak Cryptography for Passwords
- Permissions, Privileges, and Access Controls
- Least Privilege Violation
- Improper Authorization
- Improper Certificate Validation
- Cryptographic Issues
- Use of Insufficiently Random Values
- Insufficient Verification of Data Authenticity
- Improperly Implemented Security Check for Standard
- Exposure of Private Information ('Privacy Violation')
- Reliance on Cookies without Validation and Integrity Checking
- Client-Side Enforcement of Server-Side Security
- Insufficient Compartmentalization
- Reliance on a Single Factor in a Security Decision
- Insufficient Psychological Acceptability
- Reliance on Security Through Obscurity
- Protection Mechanism Failure
- Insufficient Logging
- Logging of Excessive Data
- Use of Hard-coded Credentials
- Reliance on Untrusted Inputs in a Security Decision
and
- Improper Neutralization of Special Elements used in a Command ('Command Injection')
- Improper Neutralization of Input During Web Page Generation ('Cross-site Scripting')
- Improper Neutralization of Special Elements used in an SQL Command ('SQL Injection')
- Improper Control of Resource Identifiers ('Resource Injection')
respectively.
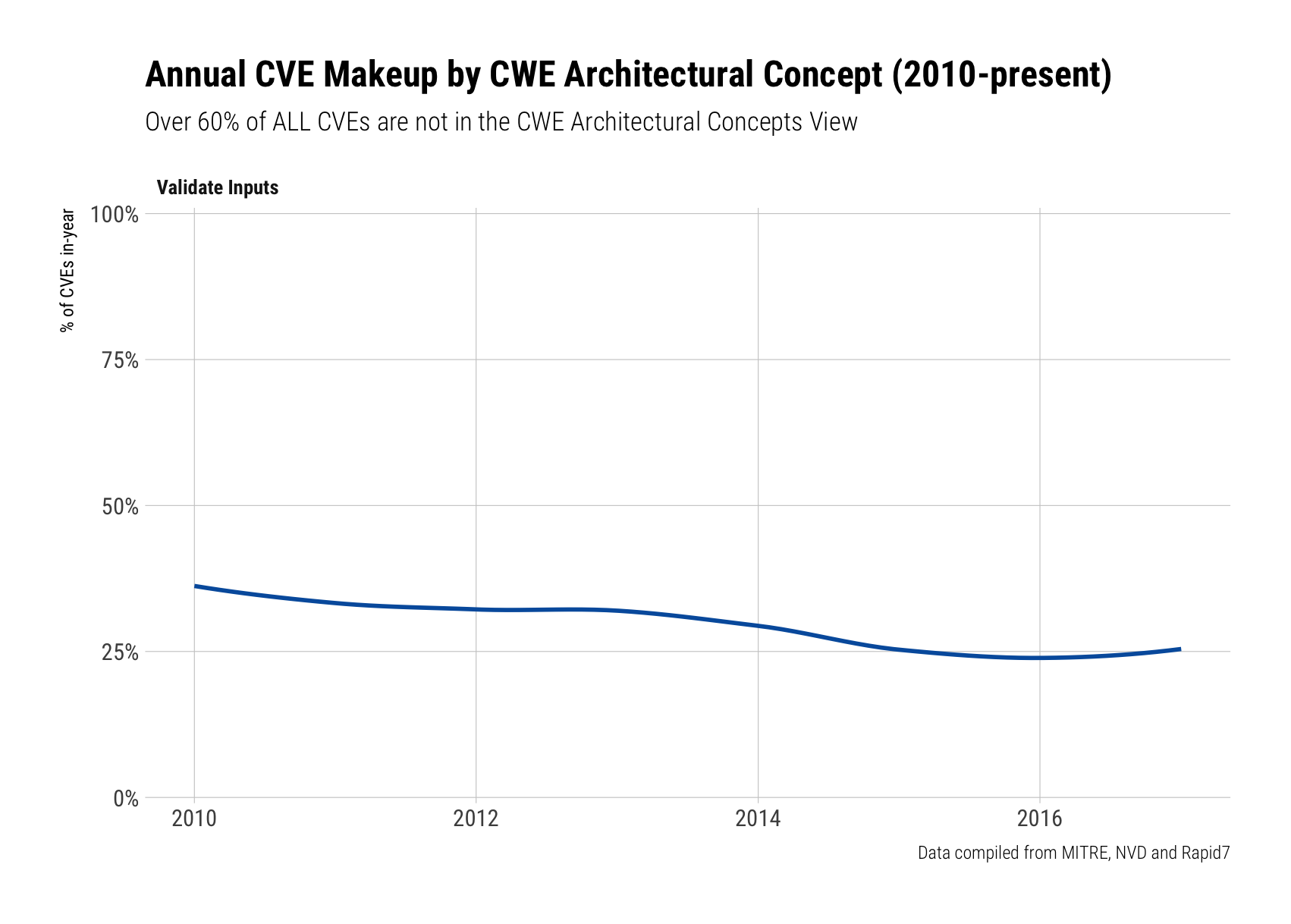
Architectural Concepts
Another research area that had potential for interesting results was "Architectural Concepts". Out of all of them:
- Audit
- Authenticate Actors
- Authorize Actors
- Cross Cutting
- Encrypt Data
- Identify Actors
- Limit Access
- Limit Exposure
- Lock Computer
- Manage User Sessions
- Validate Inputs
- Verify Message Integrity
"Validate Inputs" was the only category with any real representation in the data. Thankfully, it's on a somewhat downward trajectory (though it makes up nearly 25% of CVEs):
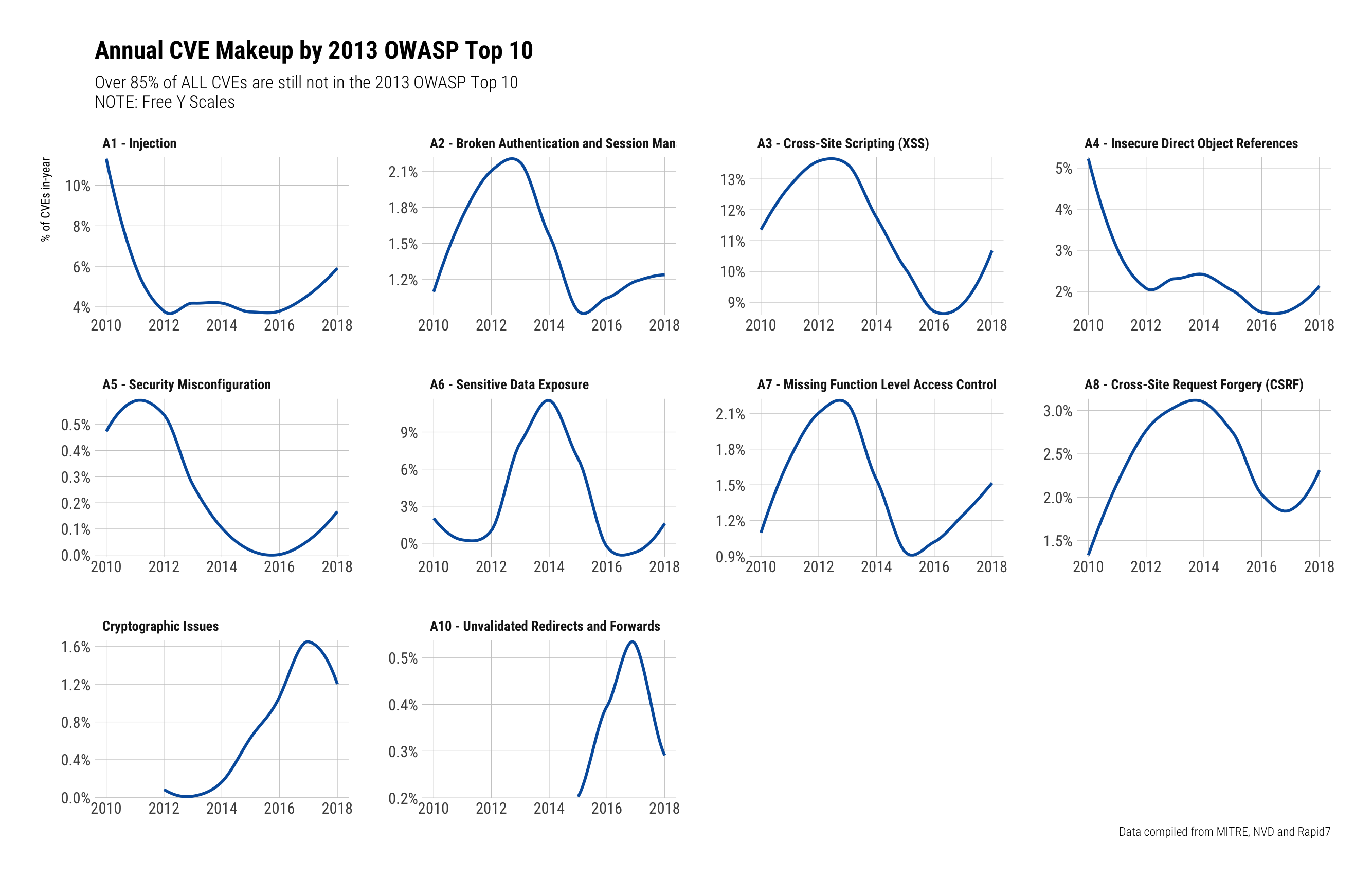
OWASP Top 10
Our final look (today) is at the (2013) OWASP Top 10 and it's no surprise that cross-site scripting and injection attacks dominate this view since they tend to be targets of choice for researchers (and attackers):
There are may other Research Concepts areas you can explore for both your own data (you are tracking CWEs in your application development lifecycle, right?) and for general CVE data.
Future posts may explore even deeper dives into the CVE ecosystem by vendor, technology and "operations impact". If there are any views you'd like to see or find out more about how we analyzed the data, send a note to research@rapid7.com.