Last updated at Wed, 29 Nov 2017 21:12:54 GMT
When security operations centers or security teams have data output from our security devices or from threat intelligence sources, it all too often lacks any sort of reasonable context on which to base an investigation.
When we have Indicators of Compromise (IoCs) that define a particular type of attack, often largely IP addresses and file hashes, this can make a very difficult starting place; inefficient at best, paralyzing at worst. Data with no intelligence lacks context and we need context in order to succeed. Let’s use a real world example to demonstrate this.
Grizzly Steppe
A somewhat recent example that we can look to for contextual issues can be seen in the attacks that occurred during the 2016 US election, which came to be known by the code name Grizzly Steppe. These attacks, purported to have been carried out by the Russian Intelligence Services (RIS), attempted to influence the course of the election through exfiltration and exposure of sensitive information, undermining of confidence in the election process, and disruption of critical infrastructure, all backed by a variety of phishing attacks, malware, stolen credentials, and a host of other means.
In an effort to combat these attacks, the US Department of Homeland Security (DHS) and the Office of the Director of National Intelligence (DNI), released a Joint Analysis Report (JAR) in December of 2016. Accompanying the report was a file containing IoCs that might be used to detect the presence of the Grizzly Steppe attack groups, Fancy Bear (APT28) and Cozy Bear (APT29), in a given enterprise.
The Data, As Released
The IoC file contained:
- 1 URL
- 10 FQDNs
- 876 IPv4 IP addresses
- 1 YARA rule
- 24 file hashes, 7 with accompanying file information
Unfortunately, much of the information was very general, and a large portion of the included IPs pointed to the address space of large cloud companies such as Google, Yahoo, and Twitter. While this is not necessarily incorrect, as the attackers were indeed making use of these services, it is not useful from an investigative standpoint.
If we were to query a security device, such as a Security Information Event Monitoring (SIEM) tool, with these IoCs, we would be returned an enormous number of results in most environments, as we would be asking for information about very common user activity. In particular, the results in the Grizzly Steppe IoC was so general that it would return literally millions of results when querying the common set of security devices in a large enterprise environment.
Given this, is there anything we can do to get to a place where we have something that our Incident Response team can actually sink their teeth into? Fortunately, yes there is.
Gaining a Little Context
In order to get something useful from the general information that we have, we can do a bit of analysis on it using various tools. Many of these analysis tasks are very similar in nature, so one we have tooling for our efforts, we can continue to reuse and refine it whenever we have reason to apply it again. Here we will be focusing on the IP addresses and file hashes.
IP Addresses
We can query Shodan about the IP information that we have, making use of the command line client. Let’s take a quick look at the first IP:
Shodan host 167.114.35.70
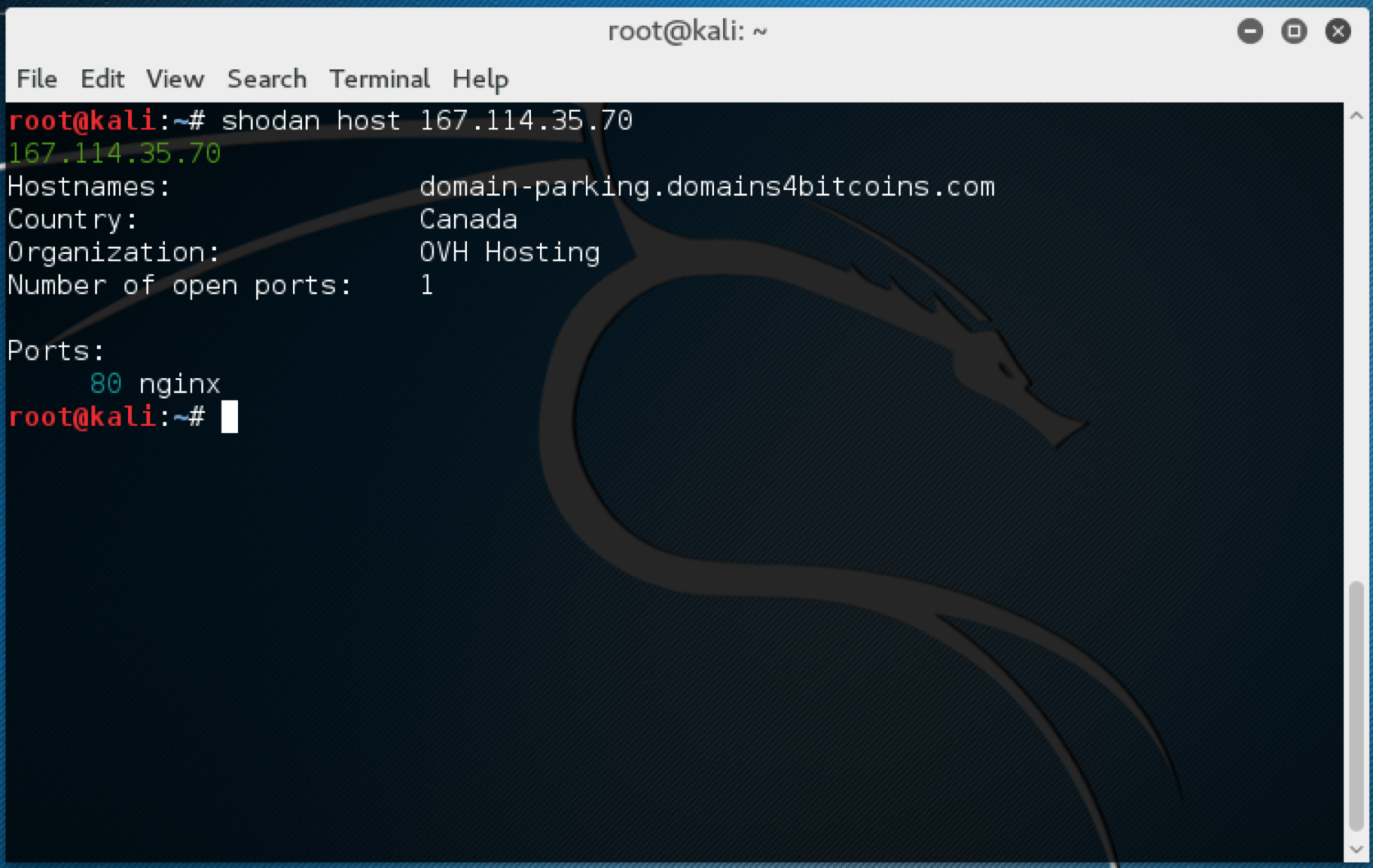
We can see a bit of basic information about that one -- nothing much interesting there, but let’s look at all the rest of them. For this, we’ll want to use a script, and there are a host of existing examples that we can make use of. We’ll pull the IPs out of the IoC file into their own text file called hosts, and use a script from John Matherly, the developer of Shodan, to process the IPs and download the information:
python ./shodan-ip-download.py hosts hosts.json.gz
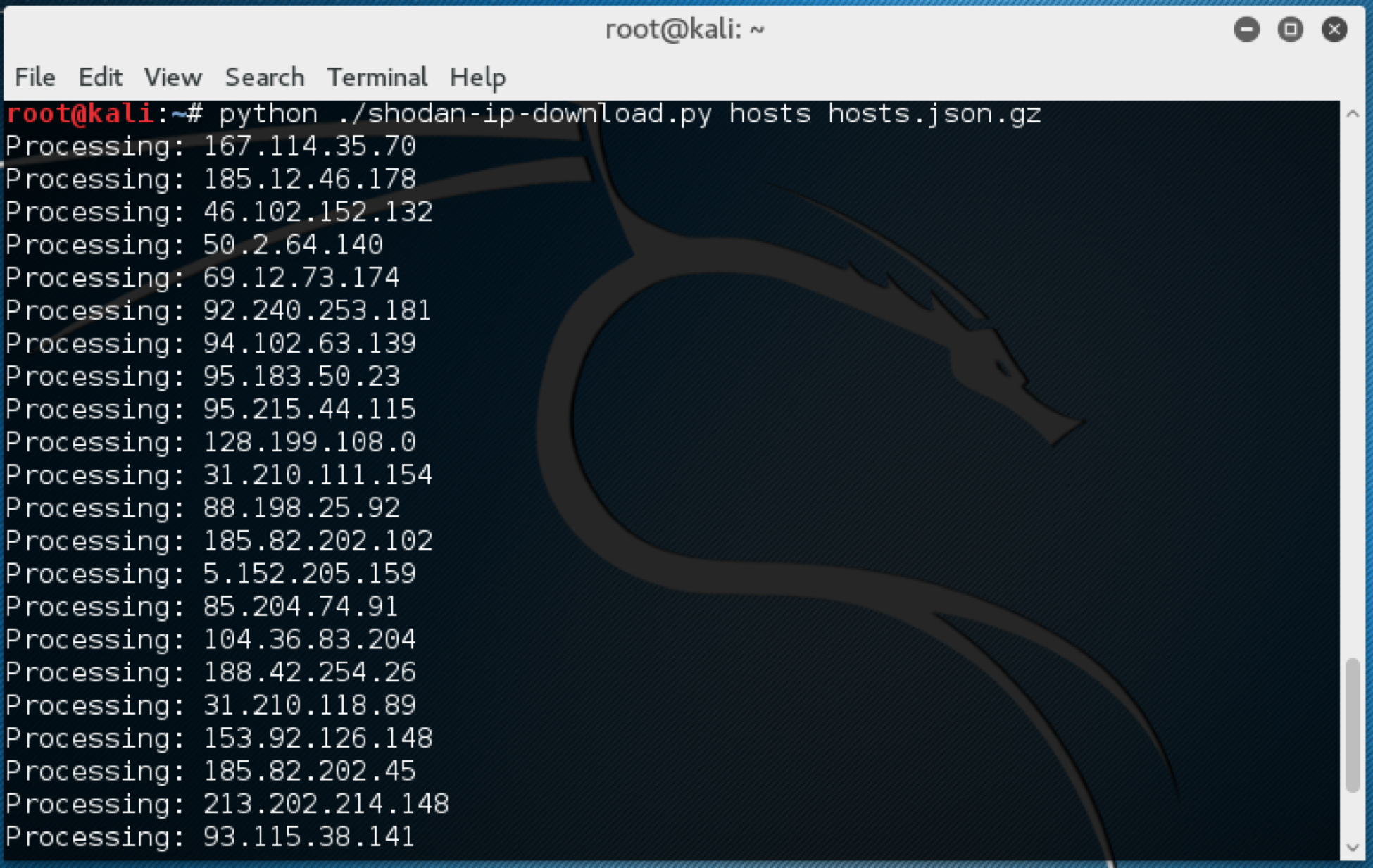
We will end up with a json formatted file, suitable for parsing with the Shodan command line tool, like so:
shodan parse --separator , hosts.json.gz
This will give us a CSV file which we can then browse at our leisure.
Upon doing so, one of the interesting points of information is that many of the IP addresses, about 20%, are Tor exit nodes.
File Hashes
To handle the file hashes, we can likely submit these to an anti-malware platform in our environment. However, it might be nice to know a bit more about them. After all, if the files listed in the IoC are malware, we’ll likely see new variants of them shortly, and it might be nice to have some idea what family we should be looking out for in general. For this, we can turn to VirusTotal.
For the very small number of files that we are dealing with, 24 as we mentioned earlier, we could just bang them through the VirusTotal search field, returning some interesting commentary:
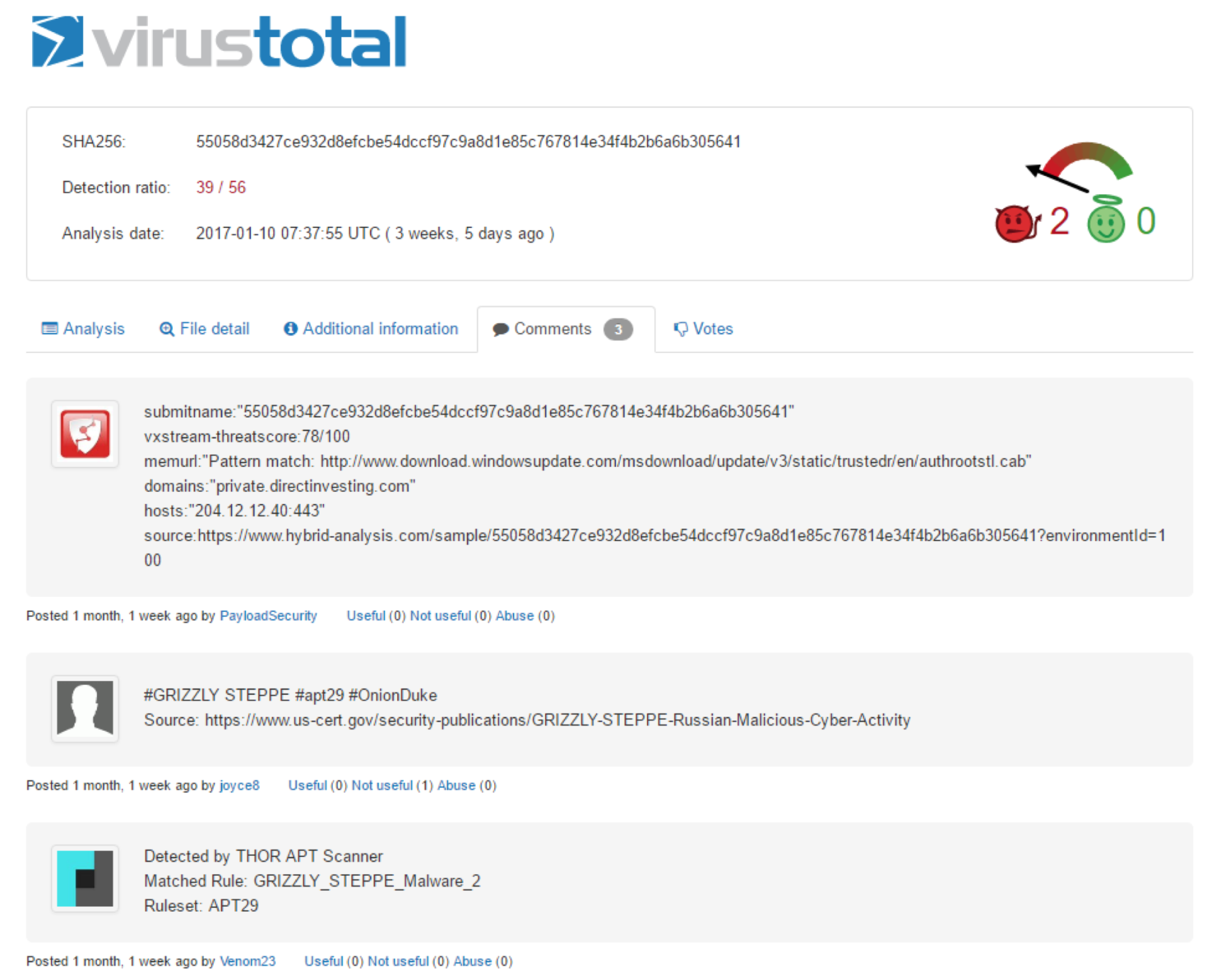
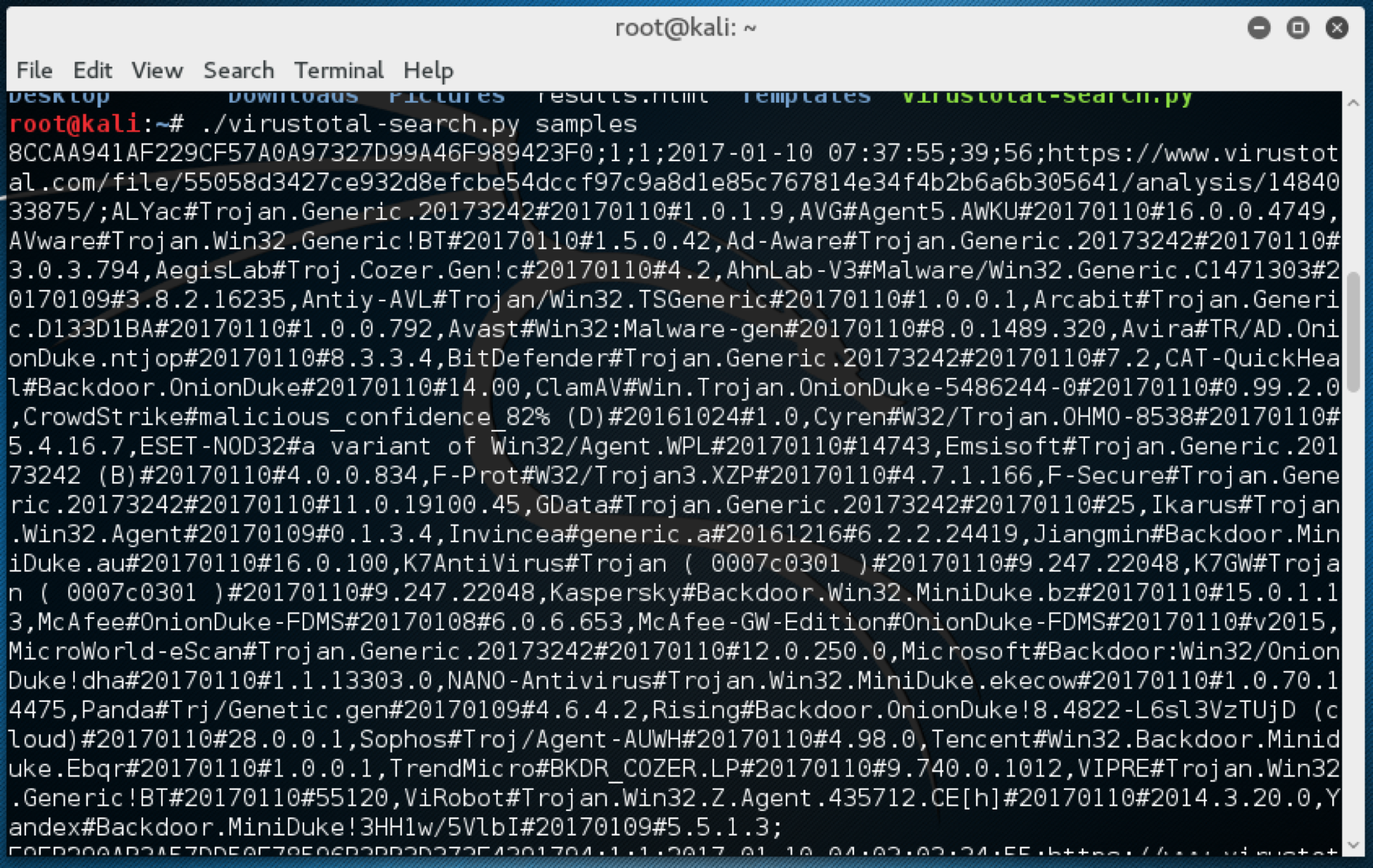
This works, but doesn’t scale well. Fortunately, Didier Stevens has a Python tool to help us out with this very problem. We can provide the script with a list of all of the files hashes from the IoC file that we have, in a text file called samples, and it will dutifully ask VirusTotal (we’ll need an API key for this) about them, which will ultimately provide a CSV file back to us with all of the results:
./virustotal-search.py samples
You can also use Komand to automate the data enrichment process from both Shodan and VirusTotal. The data would like something like this:
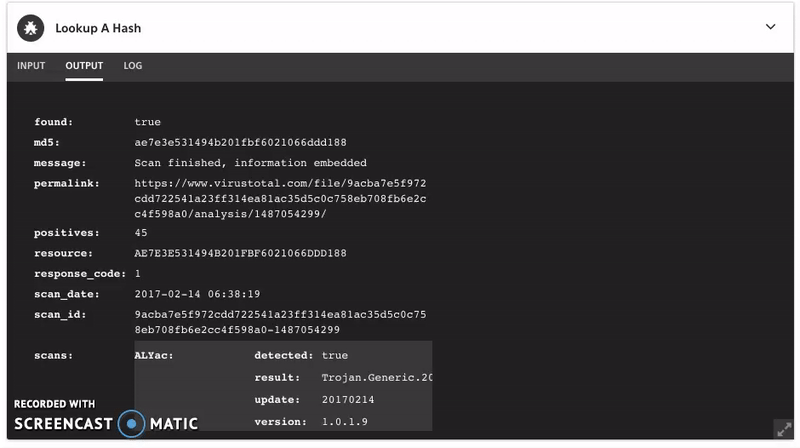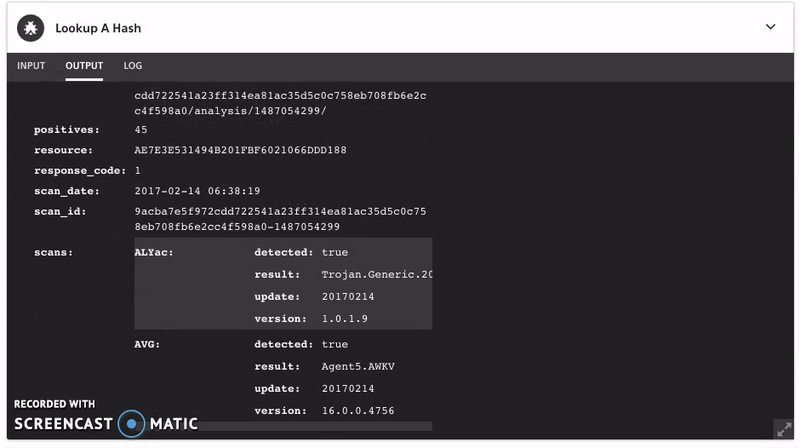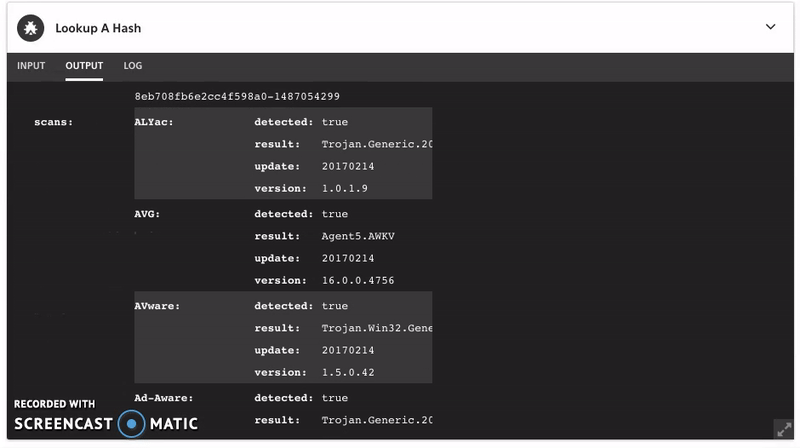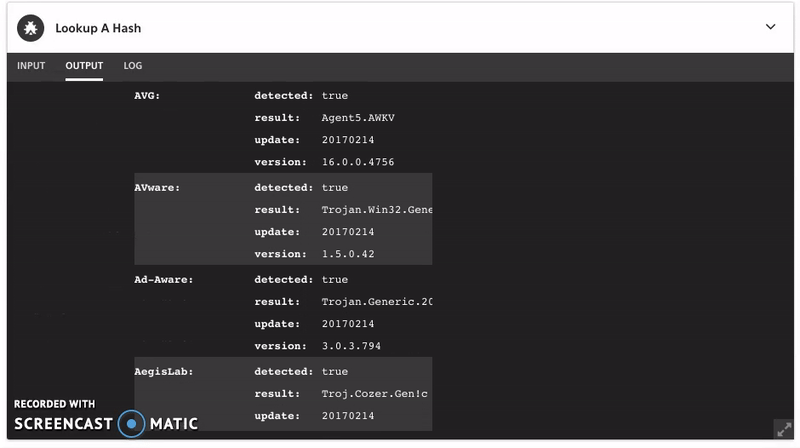
Where do we go now that we have a bit more specific data? Now we go investigate a bit. We have a much more specific list of IP addresses to work with. Presuming that the use of Tor is not common in our environment, this is a good place to start.
From there, we can see what else the systems using Tor have been touching internally and investigate further. We also have a good set of malware, and potentially variants, to investigate. Both of these items are specific enough that we may get a more manageable set of results out of querying our SIEM.
Once we have a good look at the systems that have presented themselves as being outliers among normal system activity immediately, by communicating via Tor or displaying malware-like behaviors, in addition to catching the bad guys, we can also use these results to help refine our security tools. IDSs can be tuned, YARA signatures added to our anti-malware devices, and better querying and altering configured on our SIEMs. As we discussed earlier, through developing better tools for investigation, we ease the path for ourselves the next time we need to do this.
Conclusion
In our daily duties as security professionals, we need context in order to be successful. As the old saying goes, “garbage in, garbage out”. Fortunately, with a little elbow grease, some command line kung-fu, and just a quantum of clever, we can often get to a place of better context by processing the data through a few simple tools. Like a magician’s trick, it doesn’t seem like much once we know how it was done, but these are the tactics on which much of the security industry survives.
The next time you find yourself facing down a mountain of log file or a pile of useless-looking data, get a fresh coffee, roll up your sleeves, and see where you can get by crunching the data a bit to gain some context and hone in on the interesting bits.